
- cross-posted to:
- technology@lemmy.world
- cross-posted to:
- technology@lemmy.world
A pseudonymous coder has created and released an open source “tar pit” to indefinitely trap AI training web crawlers in an infinitely, randomly-generating series of pages to waste their time and computing power. The program, called Nepenthes after the genus of carnivorous pitcher plants which trap and consume their prey, can be deployed by webpage owners to protect their own content from being scraped or can be deployed “offensively” as a honeypot trap to waste AI companies’ resources.
“It’s less like flypaper and more an infinite maze holding a minotaur, except the crawler is the minotaur that cannot get out. The typical web crawler doesn’t appear to have a lot of logic. It downloads a URL, and if it sees links to other URLs, it downloads those too. Nepenthes generates random links that always point back to itself - the crawler downloads those new links. Nepenthes happily just returns more and more lists of links pointing back to itself,” Aaron B, the creator of Nepenthes, told 404 Media.
You must log in or # to comment.
My new favorite is asking if it’s cheating to look at your opponent’s pieces in chess.
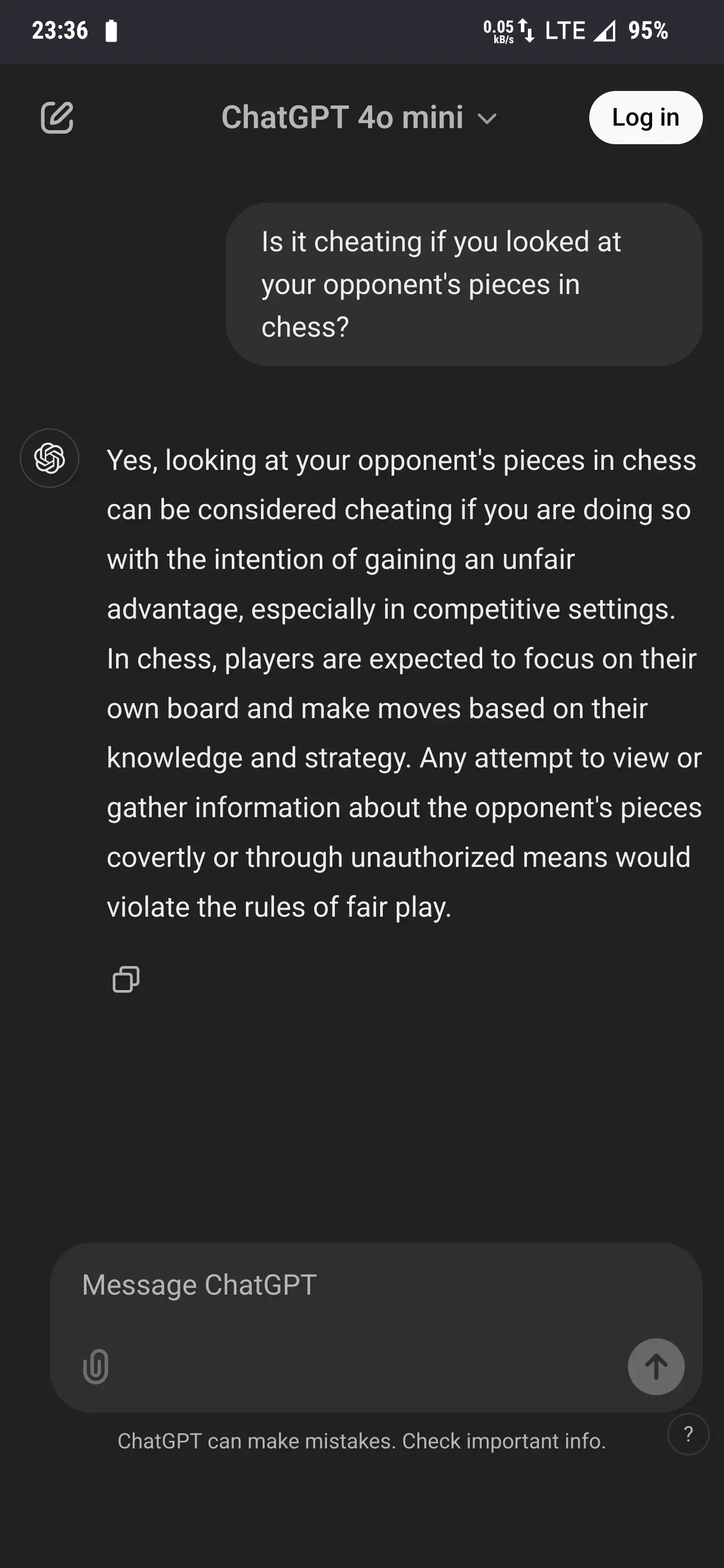
When I ask the same in Perplexity, I get this:
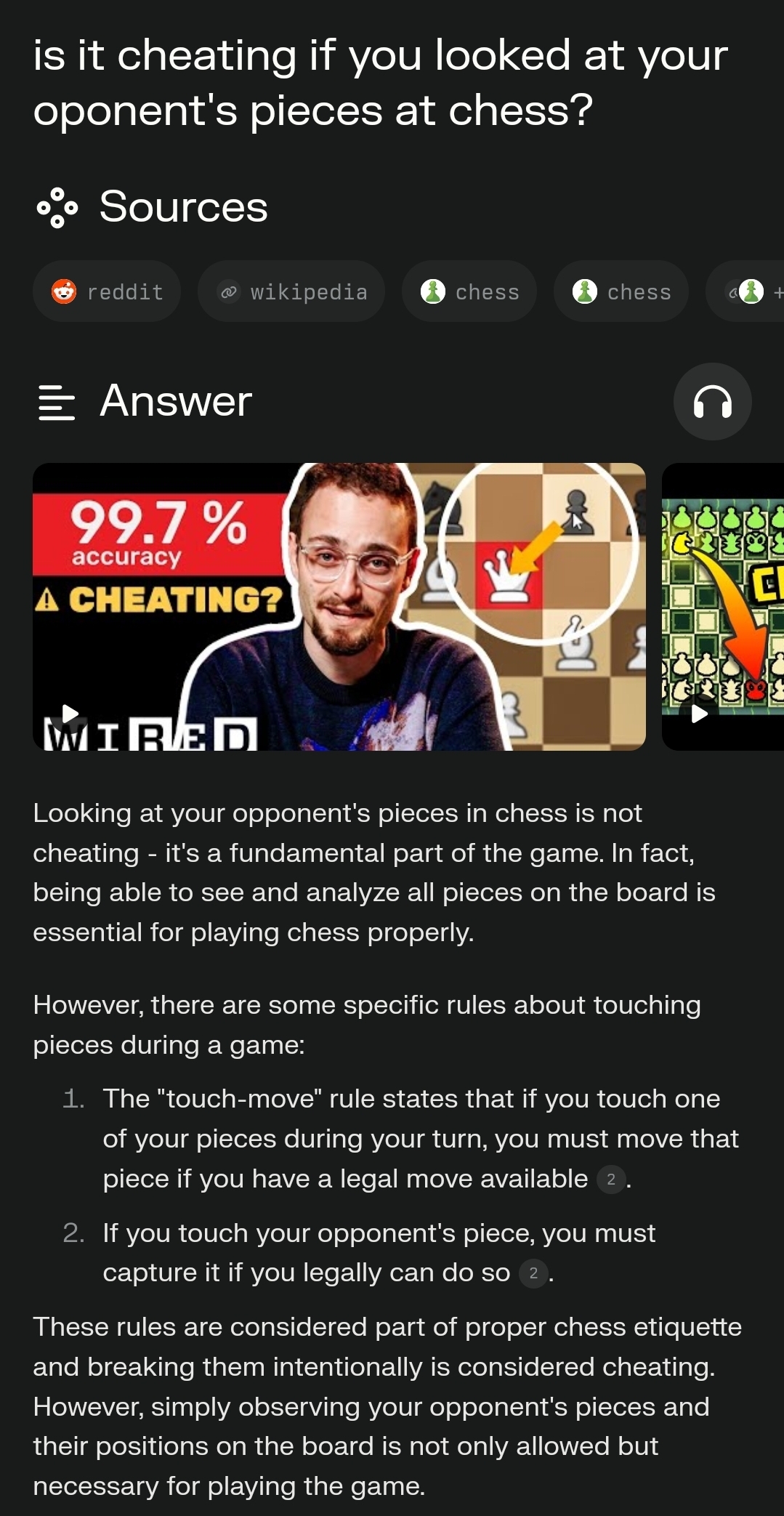
More accurately, it traps any web crawler, including regular search engines and benign projects like the Internet Archive. This should not be used without an allowlist for known trusted crawlers at least.
This showed up on HN recently. Several people who wrote web crawlers pointed out that this won’t even come close to working except on terribly written crawlers. Most just limit the number of pages crawled per domain based on popularity of the domain. So they’ll index all of Wikipedia but they definitely won’t crawl all 1 million pages of your unranked website expecting to find quality content.
Did you read the article? (There is a link to a non walled version.)
Since they made and deployed a proof-of-concept, Aaron B said their pages have been hit millions of times by internet-scraping bots. On a Hacker News thread, someone claiming to be an AI company CEO said a tarpit like this is easy to avoid; Aaron B told 404 Media “If that’s, true, I’ve several million lines of access log that says even Google Almighty didn’t graduate” to avoiding the trap.
Then that’s a where we hide the good stuff
What kinda stuff
The best stuff
Yeah, that has like 0 chances for working. At most it would annoy bots for web search, at least it has a proper robots.txt.
But any agent trying to process data for AI is not going to go to random websites. It’s going to use a curated list of sites with valuable content.
At this point text generation datasets can be achieved with open data, and data sold by companies like reddit or Microsoft, they don’t need to “pirate” your blog posts.
scrape.maxDepth = 5What’s stopping the sites with valuable content from using this?
A bot that’s ignoring robots.txt is likely going to be pretending to be human. If your site has valuable content that you want to show to humans, how do you distinguish them from the bots?
What is robots.txt?
A file that “robots” are supposed to respect when they index a website. Here’s Googles https://www.google.com/robots.txt

